- 软件


绿色版 /英文 /

绿色版 /简体中文 /

绿色版 /简体中文 /

免费版 /简体中文 /

免费版 /简体中文 /

简体中文 /
ScreamingFrogSEOSpider14是一款功能强大的网站资源检测和捕获工具。该工具可以从搜索引擎优化的角度模拟谷歌、必应等搜索引擎捕获网页,同时分析网页的结构、内容和其他信息,然后给我们详细的分析结果。用户可以通过捕获结果来分析网站数据,这样你就可以很快修复网站,非常的好用!
1、查找断开的链接,错误和重定向。
2、分析页面标题和元数据。
3、查看Meta机器人和指令。
4、审计hreflang属性。
5、发现重复页面。
6、生成XML站点地图。
7、网站可视化。
8、抓取限制(无限)。
9、调度。
10、抓取配置。
11、保存抓取并重新上传。
12、自定义源代码搜索。
13、自定义提取。
14、Google Analytics集成。
15、搜索控制台集成。
16、链接度量标准集成。
17、渲染(JavaScript)。
18、自定义robots.txt。
19、AMP爬行和验证。
20、结构化数据和验证。
21、存储和查看原始和呈现的HTML。
1、从本站下载解压后,即可得到Screaming Frog SEO Spider 14源程序和破解文件;
2、双击“ScreamingFrogSEOSpider-14.0.exe”文件运行,点击Install安装,默认安装路径,安装类型;
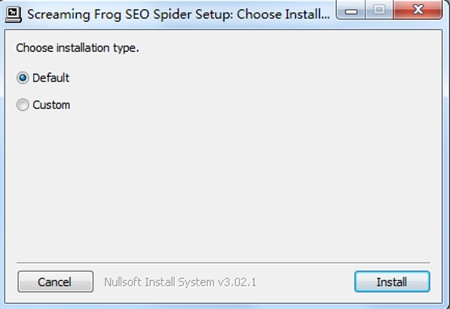
3、耐心等待软件安装完成,点击Close退出;
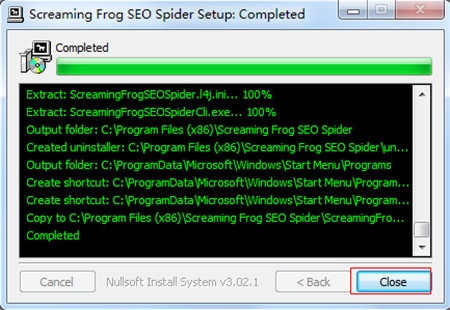
4、运行程序进入操作界面,选择Licence按钮,点击Enter Licence即可弹出激活框;

5、接着打开Keygen-NGEN夹,运行Keygen.exe注册机,将注册机中内容复制到激活框中,点击确定;
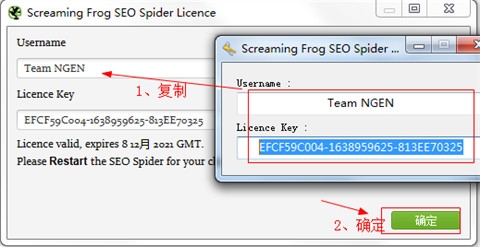
6、弹出以下所示图框,即为安装激活成功,可放心使用;
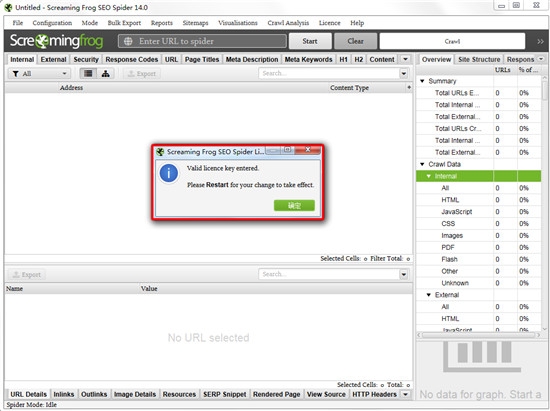
7、以上便是Screaming Frog SEO Spider 14安装教程,欢迎下载体验。
1、找到断开的链接
立即抓取网站并找到损坏的链接(404s)和服务器错误。批量导出错误和源URL以进行修复,或发送给开发人员。
2、审核重定向
查找临时和永久重定向,识别重定向链和循环,或上传URL列表以在站点迁移中进行审核。
3、分析页面标题和元数据
在抓取过程中分析页面标题和元描述,并识别网站中过长,短缺,缺失或重复的内容。
4、发现重复内容
使用md5算法检查发现完全重复的URL,部分重复的元素(如页面标题,描述或标题)以及查找低内容页面。
5、使用XPath提取数据
使用CSS Path,XPath或regex从网页的HTML中收集任何数据。这可能包括社交元标记,其他标题,价格,SKU或更多。
6、审查机器人和指令
查看被robots.txt,元机器人或X-Robots-Tag指令阻止的网址,例如‘noindex’或‘nofollow’,以及规范和rel =“next”和rel =“prev”。
7、生成XML站点地图
快速创建XML站点地图和图像XML站点地图,通过URL进行高级配置,包括上次修改,优先级和更改频率。
8、与Google Analytics集成
连接到Google AnalyticsAPI并针对抓取功能获取用户数据,例如会话或跳出率和转化次数,目标,交易和针对目标网页的收入。
9、抓取JavaScript网站
使用集成的Chromium WRS渲染网页,以抓取动态的,富含JavaScript的网站和框架,例如Angular,React和Vue.js。
10、可视化站点架构
使用交互式爬网和目录强制导向图和树形图站点可视化评估内部链接和URL结构。

都有哪些好用的爬虫软件!爬虫软件是一种能够爬取指定数据,并将数据导出到指定地方的软件。我们在做SEO网站、数据分析、淘宝京东网商工作的时候,面对浩瀚如云的图片、文字、视频,人工一个个录入就会非常的缓慢,大大影响工作效率,这时如果有机器可以一键采集那将大大提高工作效率,这里为大家罗列了一些市场上常见的爬虫软件,你可以依据自身的需求学习使用。
 WorkWin局域网监控软件v10.3.32完美免费版
网络软件 / 3.00M
WorkWin局域网监控软件v10.3.32完美免费版
网络软件 / 3.00M

 Yandex Browser(俄罗斯浏览器)v21.11.0.1999官方版
网络软件 / 140.00M
Yandex Browser(俄罗斯浏览器)v21.11.0.1999官方版
网络软件 / 140.00M
 俄罗斯浏览器Yandex Browserv22.1.0最新版
网络软件 / 0.95M
俄罗斯浏览器Yandex Browserv22.1.0最新版
网络软件 / 0.95M
 Twitch视频下载Free Twitch Downloadv5.1.3.225官方安装版
网络软件 / 46.00M
Twitch视频下载Free Twitch Downloadv5.1.3.225官方安装版
网络软件 / 46.00M
 番号搜索神器v1.0.0.5免费版
网络软件 / 2.00M
番号搜索神器v1.0.0.5免费版
网络软件 / 2.00M

 久久管家v2.2.2.0中文安装版
网络软件 / 7.00M
久久管家v2.2.2.0中文安装版
网络软件 / 7.00M
 万能种子搜索神器v3.2
网络软件 / 3.00M
万能种子搜索神器v3.2
网络软件 / 3.00M
 Tube8 Video Downloaderv3.2.3.0
网络软件 / 3.38M
Tube8 Video Downloaderv3.2.3.0
网络软件 / 3.38M

 海康威视密码v3.0.3.3
网络软件 / 34.41M
海康威视密码v3.0.3.3
网络软件 / 34.41M
 360桌面助手
360桌面助手
 搜狗浏览器10电脑版
搜狗浏览器10电脑版
 芒果tv
芒果tv
 迅雷影音
迅雷影音
 腾讯视频
腾讯视频
 网易云音乐
网易云音乐
 优酷
优酷
 金山毒霸
金山毒霸
 花椒直播
花椒直播
















 20s515钢筋混凝土及砖砌排水检查井pdf免费电子版
办公软件
20s515钢筋混凝土及砖砌排水检查井pdf免费电子版
办公软件
 图吧工具箱v2023.09正式版R2 官方安装版
系统工具
图吧工具箱v2023.09正式版R2 官方安装版
系统工具
 16g101-1图集pdf官方完整版电子版
办公软件
16g101-1图集pdf官方完整版电子版
办公软件
 视频播放软件墨鱼丸v2.0.0.1332官方安装版
影音工具
视频播放软件墨鱼丸v2.0.0.1332官方安装版
影音工具
 咩播直播软件v0.13.106官方版
影音工具
咩播直播软件v0.13.106官方版
影音工具
 尔雅新大黑(中文字体)共享软件
系统工具
尔雅新大黑(中文字体)共享软件
系统工具
 锤子解密器软件共享软件
交通出行
锤子解密器软件共享软件
交通出行
 金盾视频播放器v2022
影音工具
金盾视频播放器v2022
影音工具