- 软件


绿色版 /简体中文 /

简体中文 /

绿色版 /简体中文 /

简体中文 /

绿色版 /简体中文 /

简体中文 /
八爪鱼采集器是一款专门用来采集网页数据的网络软件,以自主研发的分布式云计算平台为核心,能够在短时间内从不同网站和网页上抓取大量规范化的数据内容,帮助用户轻松实现数据自动化采集,编辑,规范化,大大提高用户的效率。
简易采集
简易采集模式内置上百种主流网站数据源,如京东、天猫、大众点评等热门采集网站,只需参照模板简单设置参数,就可以快速获取网站公开数据。
智能采集
八爪鱼采集可根据不同网站,提供多种网页采集策略与配套资源,可自定义配置,组合运用,自动化处理。从而帮助整个采集过程实现数据的完整性与稳定性。
云采集
由5000多台云服务器支撑的云采集,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活契合业务场景,帮你提升采集效率,保障数据时效性。
API接口
通过八爪鱼API,可以轻松获取八爪鱼任务信息和采集到的数据,灵活调度任务,比如远程控制任务启动与停止,高效实现数据采集与归档。基于强大的API体系,还可以无缝对接公司内部各类管理平台,实现各类业务自动化。
自定义采集
针对不同用户的采集需求,八爪鱼可提供自动生成爬虫的自定义模式,可准确批量识别各种网页元素,还有翻页、下拉、ajax、页面滚动、条件判断等多种功能,支持不同网页结构的复杂网站采集,满足多种采集应用场景。
便捷定时功能
简单几步点击设置,即可实现采集任务的定时控制,不论是单次采集的定时设置,还是预设某一天或是每周每月的定时采集,都可以同时对多个任务自由进行设置,根据需要对选择时间进行多重组合,灵活调配自己的采集任务。
全自动数据格式化
八爪鱼内置了强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能,采集过程中全自动处理,无需人工干预,即可得到所需格式数据。
多层级采集
很多主流新闻、电商类的网站,里面包含一级商品列表页,也包含二级商品详情页,还有三级评论详情页面;不论网站有多少层级,八爪鱼都可以不限制层级的采集数据,满足各类业务采集需求。
支持网站登录后采集
八爪鱼内置了采集登录模块,只需配置目标网站的账号密码,即可用该模块采集到登录后的数据;同时八爪鱼还具备采集Cookie自定义功能,首次登录以后,可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站的采集。
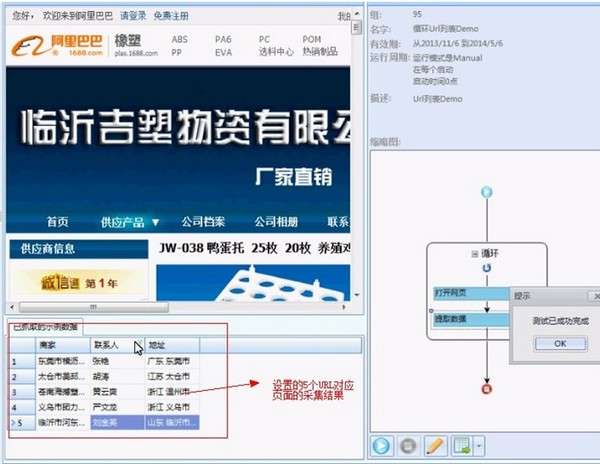
先我们新建一个任务-->进入流程设计页面-->添加一个循环步骤到流程中-->选中循环步骤-->勾选上软件右方的URL 列表勾选框-->打开URL列表文本框-->将准备好的URL列表填写到文本框中。
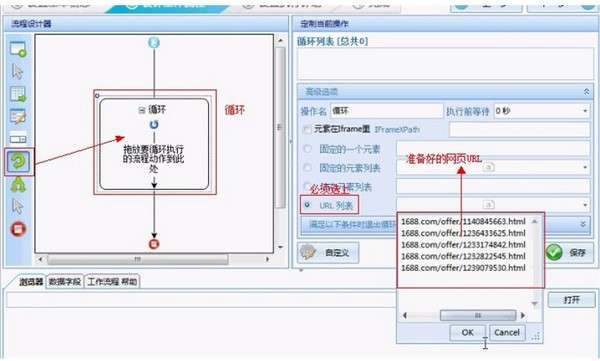
接下来往循环中拖入一个打开网页的步骤-->选中打开网页步骤-->勾选上使用当前循环里的URL作为导航地址-->点击保存。系统会在界面下方的浏览器中打开循环中选中的URL对应的网页。
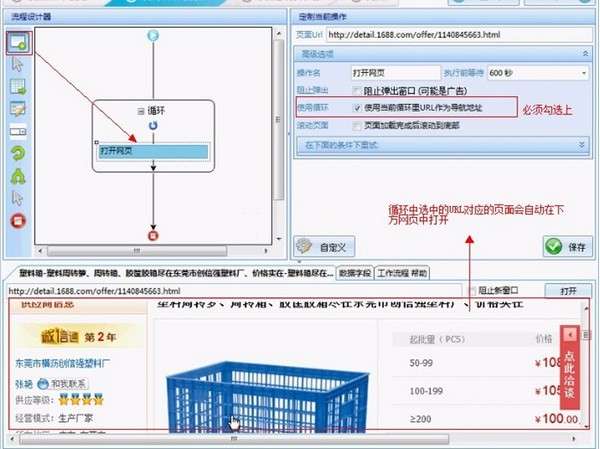
到这里,循环打开网页的流程就配置完成了,运行流程的时候,系统会逐个的打开循环中设置的URL。最后我们不需要配置一个采集数据的步骤,这里就不在多讲,大家可以参考从入门到精通系列1:采集单个网页 这篇文章。下图就是最终和流程。
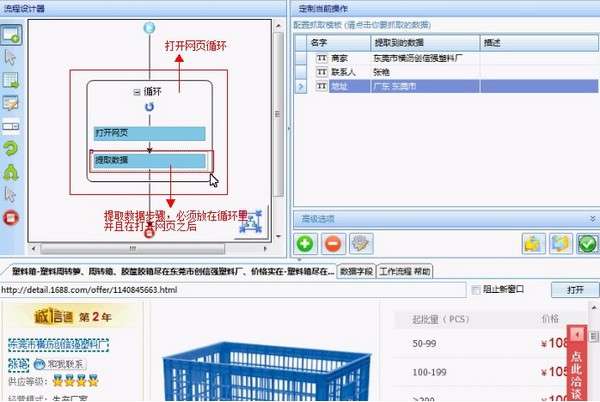
下面是流程最终的运行结果。
迭代功能
优化数据预览刷新机制
优化全部字段面板
Bug修复
修复复制粘贴步骤的问题
修复数据预览二级面板点选按钮异常问题
修复自动识别后登录显示异常问题
修复修改循环步骤方式页面异常跳转问题
修复字段预览显示排序不正确问题
 WorkWin局域网监控软件v10.3.32完美免费版
网络软件 / 3.00M
WorkWin局域网监控软件v10.3.32完美免费版
网络软件 / 3.00M

 Yandex Browser(俄罗斯浏览器)v21.11.0.1999官方版
网络软件 / 140.00M
Yandex Browser(俄罗斯浏览器)v21.11.0.1999官方版
网络软件 / 140.00M
 俄罗斯浏览器Yandex Browserv22.1.0最新版
网络软件 / 0.95M
俄罗斯浏览器Yandex Browserv22.1.0最新版
网络软件 / 0.95M
 Twitch视频下载Free Twitch Downloadv5.1.3.225官方安装版
网络软件 / 46.00M
Twitch视频下载Free Twitch Downloadv5.1.3.225官方安装版
网络软件 / 46.00M
 番号搜索神器v1.0.0.5免费版
网络软件 / 2.00M
番号搜索神器v1.0.0.5免费版
网络软件 / 2.00M

 久久管家v2.2.2.0中文安装版
网络软件 / 7.00M
久久管家v2.2.2.0中文安装版
网络软件 / 7.00M
 万能种子搜索神器v3.2
网络软件 / 3.00M
万能种子搜索神器v3.2
网络软件 / 3.00M
 Tube8 Video Downloaderv3.2.3.0
网络软件 / 3.38M
Tube8 Video Downloaderv3.2.3.0
网络软件 / 3.38M

 海康威视密码v3.0.3.3
网络软件 / 34.41M
海康威视密码v3.0.3.3
网络软件 / 34.41M
 360桌面助手
360桌面助手
 搜狗浏览器10电脑版
搜狗浏览器10电脑版
 芒果tv
芒果tv
 迅雷影音
迅雷影音
 腾讯视频
腾讯视频
 网易云音乐
网易云音乐
 优酷
优酷
 金山毒霸
金山毒霸
 花椒直播
花椒直播









 20s515钢筋混凝土及砖砌排水检查井pdf免费电子版
办公软件
20s515钢筋混凝土及砖砌排水检查井pdf免费电子版
办公软件
 图吧工具箱v2023.09正式版R2 官方安装版
系统工具
图吧工具箱v2023.09正式版R2 官方安装版
系统工具
 16g101-1图集pdf官方完整版电子版
办公软件
16g101-1图集pdf官方完整版电子版
办公软件
 视频播放软件墨鱼丸v2.0.0.1332官方安装版
影音工具
视频播放软件墨鱼丸v2.0.0.1332官方安装版
影音工具
 咩播直播软件v0.13.106官方版
影音工具
咩播直播软件v0.13.106官方版
影音工具
 尔雅新大黑(中文字体)共享软件
系统工具
尔雅新大黑(中文字体)共享软件
系统工具
 锤子解密器软件共享软件
交通出行
锤子解密器软件共享软件
交通出行
 金盾视频播放器v2022
影音工具
金盾视频播放器v2022
影音工具