- 软件


/简体中文 /

/简体中文 /

/简体 /

/简体中文 /

/简体中文 /

/简体中文 /
汉王PDF OCR,一款具有识别正确率高,识别速度快特点的OCR图片文字识别软件,它支持批量处理功能,避免了单页处理的麻烦。汉王OCR支持处理灰度、彩色、黑白三种色彩的BMP、TIF、JPG、PDF多种格式的图像文件。
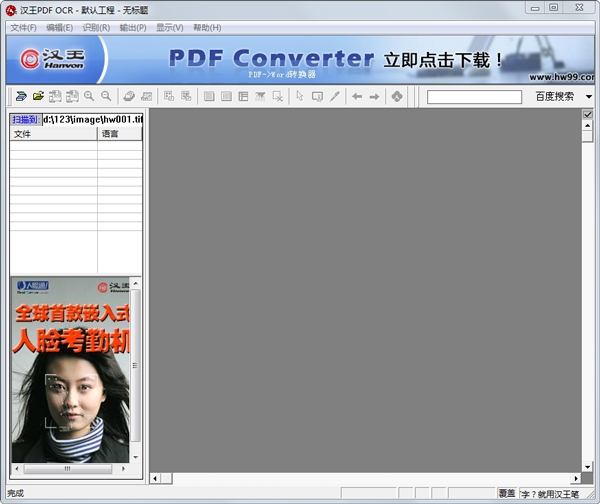
光学字符识别(英语:Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。OCR的概念是在1929年由德国科学家Tausheck最先提出来,并申请了专利。后来美国科学家Handel也提出了利用技术对文字进行识别的想法。国内最早的OCR商业应用是由中国科学家王庆人教授在南开大学开发出来的,并在美国市场投入商业使用。
1.图像输入、图像前处理、预识别。
2.图像输入
对于不同的图像格式,有着不同的存储格式,不同的压缩方式,目前有OpenCV、CxImage等开源项目。
3.预处理
主要包括二值化,噪声去除,倾斜较正等。
4.二值化
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,可以简单的分为前景与背景,为了让计算机更快的、更好地识别文字,我们需要先对彩色图进行处理,使图片只前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图。
5.噪声去除
对于不同的文档,对噪声的定义可以不同,根据噪声的特征进行去燥,就叫做噪声去除。
6.倾斜校正
由于一般用户,在拍照文档时,都比较随意,因此拍照出来的图片不可避免的产生倾斜,这就需要文字识别软件进行较正。
7.版面分析
将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,目前还没有一个固定的,最优的切割模型。
8.字符切割
由于拍照条件的限制,经常造成字符粘连,断笔,因此极大限制了识别系统的性能。
9.字符识别
这一研究已经是很早的事情了,比较早有模板匹配,后来以特征提取为主,由于文字的位移,笔画的粗细,断笔,粘连,旋转等因素的影响,极大影响特征的提取的难度。
10.版面还原
人们希望识别后的文字,仍然像原文档图片那样排列着,段落不变,位置不变,顺序不变地输出到Word文档、PDF文档等,这一过程就叫做版面还原。
11.后处理、校对
根据特定的语言上下文的关系,对识别结果进行校正,就是后处理。
1.在开始菜单中打开OCR软件。
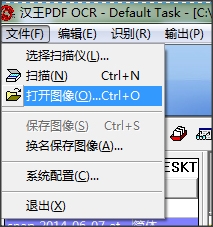
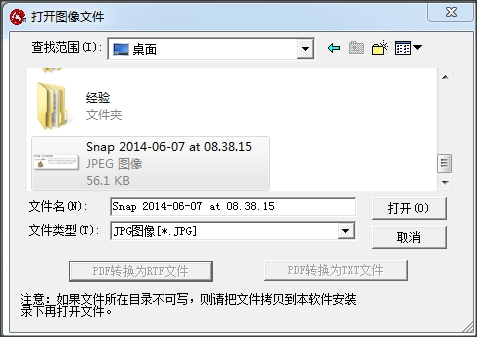
2.点击【文件】-【打开图像文件】,选择一副包含文字的图片。
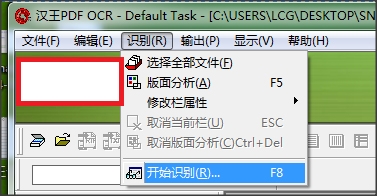
3.点击【识别】-【开始识别】。
4.软件会识别出图片上的文字,可以对一些识别错误的字进行修改。

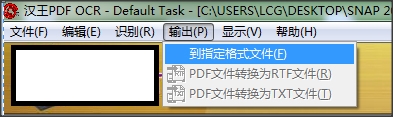
5.修改完成后点击【输出】-【到指定格式】,保存识别出来的文本。
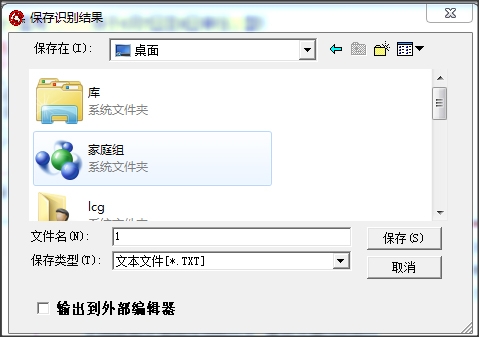
6.可以打开保存的文本,将文本复制到word等软件处进行二次编辑。
对部分功能进行了优化。

 20s515钢筋混凝土及砖砌排水检查井pdf免费电子版
办公软件 / 12.00M
20s515钢筋混凝土及砖砌排水检查井pdf免费电子版
办公软件 / 12.00M

 16g101-1图集pdf官方完整版电子版
办公软件 / 31.00M
16g101-1图集pdf官方完整版电子版
办公软件 / 31.00M
 16g101-3图集pdf版电子版
办公软件 / 43.00M
16g101-3图集pdf版电子版
办公软件 / 43.00M
 Runway(AI机器人训练软件)v0.13.1
办公软件 / 75.00M
Runway(AI机器人训练软件)v0.13.1
办公软件 / 75.00M

 牛眼看书v2.0
办公软件 / 0.63M
12d101-5图集官方免费版完整版
办公软件 / 27.00M
牛眼看书v2.0
办公软件 / 0.63M
12d101-5图集官方免费版完整版
办公软件 / 27.00M
 cruise软件官方版
办公软件 / 1000.00M
cruise软件官方版
办公软件 / 1000.00M
 12j003室外工程图集免费版
办公软件 / 6.00M
12j003室外工程图集免费版
办公软件 / 6.00M
 20以内加减法练习题17*100题pdf免费版
办公软件 / 1.00M
20以内加减法练习题17*100题pdf免费版
办公软件 / 1.00M
 九方智投旗舰版v3.15.0官方版
办公软件 / 96.94M
九方智投旗舰版v3.15.0官方版
办公软件 / 96.94M

 360桌面助手
360桌面助手
 搜狗浏览器10电脑版
搜狗浏览器10电脑版
 芒果tv
芒果tv
 迅雷影音
迅雷影音
 腾讯视频
腾讯视频
 网易云音乐
网易云音乐
 优酷
优酷
 金山毒霸
金山毒霸
 花椒直播
花椒直播





 万兴PDF专家
免费软件 / 2.11M
万兴PDF专家
免费软件 / 2.11M
 图吧工具箱v2023.09正式版R2 官方安装版
系统工具
图吧工具箱v2023.09正式版R2 官方安装版
系统工具
 视频播放软件墨鱼丸v2.0.0.1332官方安装版
影音工具
视频播放软件墨鱼丸v2.0.0.1332官方安装版
影音工具
 咩播直播软件v0.13.106官方版
影音工具
咩播直播软件v0.13.106官方版
影音工具
 尔雅新大黑(中文字体)共享软件
系统工具
尔雅新大黑(中文字体)共享软件
系统工具
 锤子解密器软件共享软件
交通出行
锤子解密器软件共享软件
交通出行
 快播5.0v5.8.130免费版标准版
影音工具
快播5.0v5.8.130免费版标准版
影音工具
 金盾视频播放器v2022
影音工具
金盾视频播放器v2022
影音工具